









Small Language Models are the Future of Agentic AI
Мы привыкли думать, что в мире искусственного интеллекта размер имеет значение. Гигантские языковые модели (LLM), такие как те, что лежат в основе ChatGPT, поражают воображение своей способностью писать стихи, генерировать код и вести философские беседы. Технологические гиганты вкладывают миллиарды в создание всё более крупных и мощных «мозгов» для ИИ. Но что, если этот путь — тупик?
Недавняя работа исследователей из NVIDIA, одного из флагманов индустрии, бросает вызов этой идее. В своей статье «Малые языковые модели — будущее агентоподобного ИИ» они утверждают: будущее не за монструозными универсалами, а за командами быстрых, дешевых и эффективных «специалистов» — малых языковых моделей (SLM).
Проблема с гигантами: дорого и неэффективно
Сегодня большинство ИИ-агентов — программ, которые не просто отвечают на вопросы, а выполняют за нас задачи (бронируют билеты, планируют проекты, управляют умным домом) — работают на огромных LLM. Это похоже на использование суперкомпьютера для работы с калькулятором.
Представьте, что вы просите своего ИИ-помощника добавить встречу в календарь. За кулисами ваш простой запрос отправляется в огромный дата-центр, где его обрабатывает модель с сотнями миллиардов параметров, способная анализировать Шекспира. Результат — это работает, но это:
- Дорого: Каждый такой запрос стоит реальных денег, что выливается в астрономические счета за облачные вычисления для разработчиков и высокие цены на подписку для пользователей.
- Медленно: Передача данных и обработка на гигантской модели создают задержку.
- Избыточно: 99% мощности модели не используется для такой простой задачи.
Исследователи NVIDIA говорят, что мы попали в ловушку: мы используем универсальный «мозг» для выполнения узкоспециализированных, повторяющихся задач. Это экономически неэффективно и экологически нерационально.
Решение: команда узких специалистов
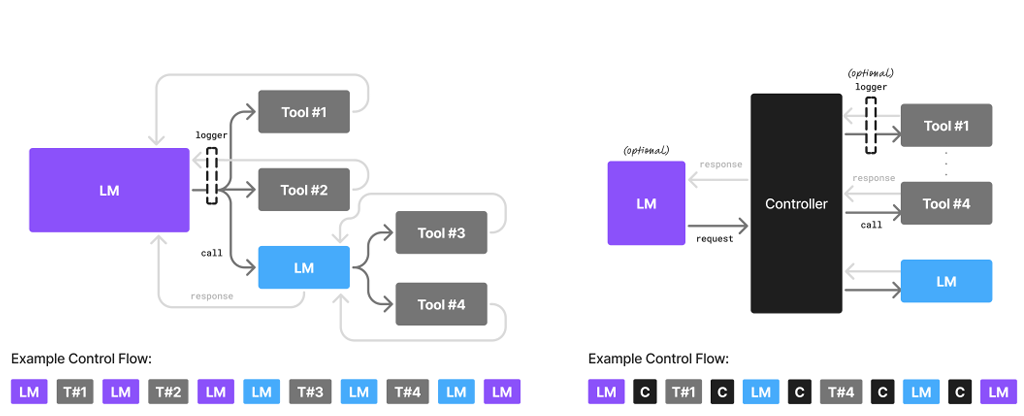
Что же предлагают взамен? Идею, которая давно используется в инженерии и бизнесе — модульность. Вместо одного гигантского, неповоротливого ИИ-гения — целая команда малых языковых моделей (SLM), каждая из которых натренирована на свою задачу.
SLM — это нейросеть, достаточно компактная, чтобы работать на обычном ноутбуке или даже смартфоне. Она не сможет рассуждать о смысле жизни, но идеально выполнит свою функцию.
Как это будет работать на практике?
Представим того же ИИ-агента, но построенного на SLM-архитектуре. Вы просите его спланировать поездку.
- Главный «диспетчер» (маленькая SLM) принимает ваш запрос «Спланируй поездку в Санкт-Петербург на выходные».
- Он распознает подзадачи и вызывает других «специалистов»:
- SLM-поисковик авиабилетов обращается к API авиакомпаний и находит лучшие варианты.
- SLM-отельер ищет подходящие отели по вашим критериям.
- SLM-гид составляет краткий список достопримечательностей.
- SLM-секретарь красиво форматирует всю информацию в единый план.
Каждая из этих моделей мала, работает молниеносно и потребляет минимум ресурсов. И только если вы зададите сложный, открытый вопрос, вроде «Расскажи об архитектурных особенностях барокко в Петербурге», система может обратиться за помощью к большой, «эрудированной» LLM.
Преимущества «маленького» подхода
Такая система, по мнению NVIDIA, превосходит текущую модель по всем фронтам:
- Экономичность: Затраты на обработку запросов могут снизиться в 10-30 раз. Это сделает ИИ-агентов доступнее для всех.
- Скорость: Ответы будут практически мгновенными, так как большая часть вычислений может происходить прямо на вашем устройстве.
- Гибкость: Гораздо проще обновить или «дообучить» одну маленькую модель (например, под новый интерфейс сайта для бронирования), чем трогать огромную LLM.
- Безопасность и конфиденциальность: Если модели работают на вашем устройстве, ваши личные данные не нужно отправлять на сторонние серверы.
Что мешает переходу?
Если все так хорошо, почему мы до сих пор не живем в мире SLM? Авторы выделяют три основных барьера:
- Инерция инвестиций: Компании уже вложили миллиарды долларов в инфраструктуру для LLM и не спешат менять курс.
- Привычка к бенчмаркам: Разработчики привыкли измерять «крутизну» моделей на общих тестах эрудиции, а не на эффективности в реальных задачах.
- Маркетинговый шум: Вся слава и внимание прессы достаются большим моделям, в то время как SLM остаются в тени.
Тем не менее, авторы уверены, что экономическая целесообразность и здравый смысл в конечном итоге победят. Они даже предлагают конкретный алгоритм, как разработчики могут постепенно переводить своих агентов с LLM на SLM, собирая данные о типичных запросах и обучая на них специализированные модели.
Академическая работа Small Language Models are the Future of Agentic AI
🚀 Как перенаправить ошибки 404 на главную или другую страницу в WordPress.
Вот полная версия статьи на русском языке: 🚀 Как перенаправить ошибки 404 на главную или другую стра…
Руководство по переменным в WP-PageNavi для WordPress
Навигация по страницам — важная часть любого блога или новостного сайта на WordPress. Один из самых …

Философия PowerShell. Часть 2: Конвейер (Pipeline), переменные, Get-Member, файл .ps1 и экспорт результатов.
❗ Важно:Я пишу про PS7 (PowerShell 7). Он отличается от PS5 (PowerShell 5). Начиная с седьмой версии…

Философия PowerShell. Части 0,1.
Contents Часть 0. Что было до PowerShell?📅 Состояние рынка оболочек на момент выхода **MS-DOS 1.0** …

Обзор сервиса WhatsMyDNS.net
WhatsMyDNS.net — это онлайн-инструмент для проверки распространения DNS-записей по всему миру. Он по…

А давайте встроим ии в powershell. Часть вторая. Поисковик спецификаций.
В прошлый раз мы увидели, как с помощью PowerShell можно взаимодействовать с моделью Gemini через ин…